
Nous avons conçu et développé un assistant virtuel permettant de faire des démonstrations de projets de recherche facilement avec un outil visuel et intuitif. Les activités de recherche ciblées par notre système se situent dans le domaine du traitement des langues ainsi que la vision par ordinateur. On peut prendre par exemple un projet de recherche, sur lequel nos encadrants travaillent, qui permet de reconnaître les notes sur une partition musicale et de jouer ces notes de musique. Notre assistant permet donc de mettre en pratique ce projet de façon ludique via de simples commandes vocales comme : « reconnais-moi cette partition de musique ». Suite à cette commande vocale, on pourrait montrer une partition musicale à la caméra, pour que l’assistant puisse la jouer. L’idée principale du projet est donc de pouvoir facilement incorporer ce genre de projets au sein d’un assistant pour rendre celui-ci plus interactif et ludique.
Notre projet demande donc à ce que l’on crée un outil simple afin que les utilisateurs puissent écrire leurs scénarios le plus rapidement et facilement possible. Un scénario est une suite d’actions utilisant les différentes fonctions de notre assistant comme la parole ou la reconnaissance vocale afin d’effectuer une tâche précise comme la démonstration d’un projet de recherche.
Nous avons conçu un assistant capable d'interagir avec l’utilisateur par différents biais comme le microphone, la caméra et éventuellement des entrées clavier. Ainsi, pour pouvoir interagir avec l’utilisateur et analyser ses faits et gestes, il faut trois principes : un moyen de capter et comprendre ses paroles, un moyen de lui répondre oralement et également un moyen de le voir. Ces trois composants de base seront utilisés à tous les niveaux du système, notamment dans les scénarios. L’assistant doit être capable de faire appel aux différents scénarios et pouvoir utiliser les bibliothèques pour interagir avec l’utilisateur.
Ensuite, nous avons fourni le plus de fonctions de haut niveau possible à l’utilisateur pour lui permettre de déployer facilement de nouvelles fonctionnalités. Donc, nous devons donc nous assurer que les capacités citées précédemment soient robustes et fiables dans tous les cas et aussi implémenter des capacités plus précises afin que l’utilisateur ait le moins de code à écrire tout en pouvant garder une liberté maximale dans l’incorporation de son projet de recherche dans l’assistant.
Enfin, nous avons rassemblé toutes ces capacités dans un noyau qui permet rapidement, juste avec la voix ou la vision, de naviguer dans les différents scénarios tout en communiquant avec un avatar de notre assistant.
Nous avons utilisé YOLOv5. C’est une implémentation de l’architecture YOLO (You Only Look Once), qui est un algorithme de détection d'objets en temps réel. En proposant la possibilité de travailler facilement avec des modèles YOLOv5, nous permettons aux utilisateurs d'exploiter les capacités avancées de détection d'objets pour diverses applications, telles que la reconnaissance d'objets en temps réel à partir du flux vidéo de la caméra, la détection de visages, la classification d'objets, et bien d'autres encore.
Nous avons distingué 2 cas bien distincts : la détection de phrases et la détection de mots courts. Pour la reconnaissance de phrases, nous utilisons la bibliothèque SpeechRecognition en utilisant la reconnaissance de Google, offrant une solution rapide et multi-langues. Concernant la reconnaissance de mots isolés, nous utilisons Whisper (reconnaissance de OpenAI) en intégrant un contexte pré enregistré pour améliorer la reconnaissance. Par exemple, l'utilisateur peut préfixer son audio par « Ma réponse est » pour les mots « oui » ou « non ».
Nous avons adopté la bibliothèque Python gTTs (Google Text To Speech), permettant de convertir rapidement du texte en fichiers MP3 dans 59 langues, dont le français, le plus souvent utilisé dans notre cas. Cette solution transforme le texte en parole et enregistre le résultat dans un fichier temporaire, que nous lisons à l'aide d’un lecteur Python fonctionnant sous Linux. Nous avons prévu deux modes de fonctionnement : synchrone et asynchrone, qui peuvent tous deux être utile dans plein de scénarios
Pour créer notre assistant, nous avons adopté une approche modulaire, permettant l'ajout progressif de fonctionnalités. Chaque fonctionnalité est définie sous forme de scénario et lors de son exécution, chaque scénario gère les interactions avec l'utilisateur et les actions nécessaires pour réaliser sa fonction spécifique. Cette approche offre une extensibilité modulaire à notre assistant.
Par exemple, un scénario peut être conçu pour jouer aux échecs. Lorsque l'utilisateur demande à jouer aux échecs, ce scénario est activé. L'utilisateur choisit alors son camp et un plateau de jeu s'affiche. Les mouvements sont effectués verbalement et le plateau se met à jour en conséquence. Bien que les commandes vocales puissent présenter des limites dans des jeux complexes comme les échecs, l'objectif principal de ces scénarios est de tester les bibliothèques fournies, telles que la synthèse vocale ou la reconnaissance de la parole, plutôt que de fournir une expérience de jeu optimale.
Pour écrire un scénario, il suffit juste d'indiquer les mots-clés permettant au noyau de savoir quand le lancer et d’implémenter les différentes fonctionnalités de notre assistant (reconnaissance vocale, synthèse, fonctions plus haut niveau…). Ensuite, il faut développer en Python la logique du scénario en fonction de ce que l’utilisateur veut réaliser.
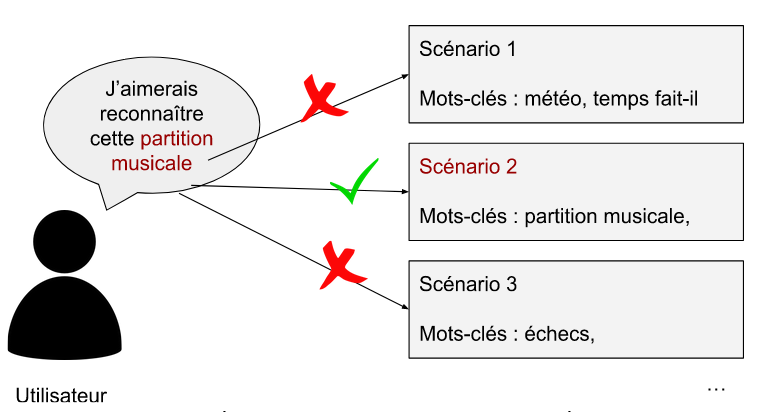
Pour permettre à notre assistant de sélectionner et d'exécuter le bon scénario en réponse à une commande vocale de l'utilisateur, nous avons mis en place un gestionnaire de scénarios. Ce gestionnaire joue un rôle essentiel en analysant d'abord la commande vocale de l'utilisateur. Il recherche ensuite parmi les scénarios existants en se basant sur une liste de mots-clés associés à chaque scénario. Une fois qu'il a identifié le scénario correspondant, il l'exécute. À la fin de l'exécution du scénario, le noyau va se mettre de nouveau en attente d’une commande vocale et répéter le même processus.
L'objectif du projet est aussi de fournir à l'utilisateur un ensemble de fonctionnalités de haut niveau pour faciliter le déploiement de nouvelles fonctionnalités. Nous avons déjà discuté des bibliothèques de base nécessaires à l'assistant, telles que la reconnaissance vocale, la synthèse vocale et l'accès à la caméra, qui simplifient l'écriture des scénarios. Toutefois, il est important de fournir des blocs de construction avancés pour minimiser la quantité de code que l'utilisateur doit écrire ou réécrire.
Pour cela, nous avons développé plusieurs scénarios en utilisant les bibliothèques de bas niveau mentionnées précédemment. Ces scénarios servent non seulement à tester l'assistant, mais aussi à fournir une base réutilisable pour de futurs scénarios similaires. En refactorisant le code commun à plusieurs scénarios, nous pouvons créer des classes génériques qui agissent comme des boîtes à outils.
Ces classes génériques encapsulent des fonctionnalités communes, comme l'accès à la caméra et l'utilisation d'un modèle de reconnaissance de texte (OCR), permettant aux scénarios d'accéder directement au texte de l'utilisateur sans avoir à réécrire ces routines. Cette abstraction facilite l'ajout de nouveaux scénarios similaires en leur permettant de simplement faire appel à ces classes et de bénéficier des fonctionnalités déjà implémentées.
Notre objectif a été d'écrire un large éventail de scénarios, en particulier dans les domaines de la vision par ordinateur et du traitement des langues, afin de fournir un ensemble complet de primitives de haut niveau. Cela permettra à l'utilisateur de parcourir la hiérarchie des classes et de choisir celles qui correspondent le mieux à ses besoins pour inclure dans ses scénarios. Une documentation détaillée de toutes les classes sera essentielle pour aider l'utilisateur à trouver rapidement les outils dont il a besoin pour implémenter de nouveaux scénarios.
En suivant cette logique nous avons pu établir un panel de scénarios à réaliser qui peuvent être intéressant de part la réutilisabilité de certaines de leurs fonctionnalités. Ces scénarios sont peut-être un peu différentes de l'utilisation réelle de l'assistant, mais ils permettent de tester facilement et dans des conditions réelles les différentes bibliothèques sur lesquelles ils reposent au travers différentes mises en situation :

Nous avons réalisé ce scénario pour pouvoir jouer à Devinsa (un projet INSA d’un jeu type “Akinator”) via notre assistant donc avec uniquement la voix. La page de Devinsa étant une page intranet accessible sur le réseau de l’INSA, nous avons eu besoin de faire du Web Scraping via la bibliothèque Sélénium afin de pouvoir manipuler la page web. Ces fonctions utilisées pourraient être utiles s’il y a d’autres scénarios de type Web Scraping à réaliser et nous allons essayer de refactoriser un maximum les fonctions utilisées dans ce scénario.

Le scénario du jeu d'échecs offre la possibilité de jouer contre Stockfish, un moteur d'échecs, en utilisant des commandes vocales pour les coups du joueur et une interface Qt pour l'affichage du plateau. Son intérêt principal réside dans la réutilisation des éléments pour la mise en place d'une interface Qt. Cependant, lors de l'attente d'une instruction vocale par l'assistant, l'application Qt se bloque en raison de la nature bloquante de la boucle principale de l'interface. Pour résoudre ce problème, l'utilisation de threads et de signaux propres à Qt est nécessaire. Cette implémentation du scénario facilite la gestion des appels bloquants pour tous les autres scénarios nécessitant une interface Qt, permettant ainsi une exécution fluide des opérations.

Dans le cadre de la conception d'un assistant de démonstration d'outil scientifique qui soit exhaustif, il était impératif d'intégré à notre architecture un modèle de traitement de texte, étant donné que ce domaine est en constante évolution. Notre choix s'est porté sur Spacy. Ce modèle est capable de traiter les instructions vocales et d'identifier les entités nommées correspondantes. Bien que ce scénario puisse ne pas être le plus pertinent, nous le considérons davantage comme une démonstration. À l'avenir, les utilisateurs pourront s'appuyer sur notre architecture et intégrer leur propre modèle de traitement de texte. Parmi les scénarios possibles figurent le traitement d'une conversation téléphonique ou d'une réunion.
Pour rendre notre assistant plus intuitif et interactif, nous allons prévoir une interface avec un avatar pour rendre la conversation avec notre assistant plus vivante. Après réflexion, nous avons décidé de partir sur une tête humaine mais pas trop réaliste pour éviter de viser un hyper-réalisme dont les imperfections seraient sans doute perçues par les utilisateurs et pourraient les déranger. Nous avons modélisé un avatar sur Blender en prévoyant des animations du mouvement de la bouche et d’aligner cela avec la synthèse vocale de l’assistant vu précédemment.
Voici les membres de l'équipe en charge de la réalisation du projet.

.png)


