
Our project aims to provide an application that simplifies the creation of annotated snippets databases.
These databases will be used to train several handwritten text recognizers.
These recognizers will be able to automatically transcribe handwritten documents (such as church and
civil registers, company documents, etc.) to make them easier to use digitally.
This project speeds up the process before we get to the recognition phase by simplifying the training
of a new recognizer.
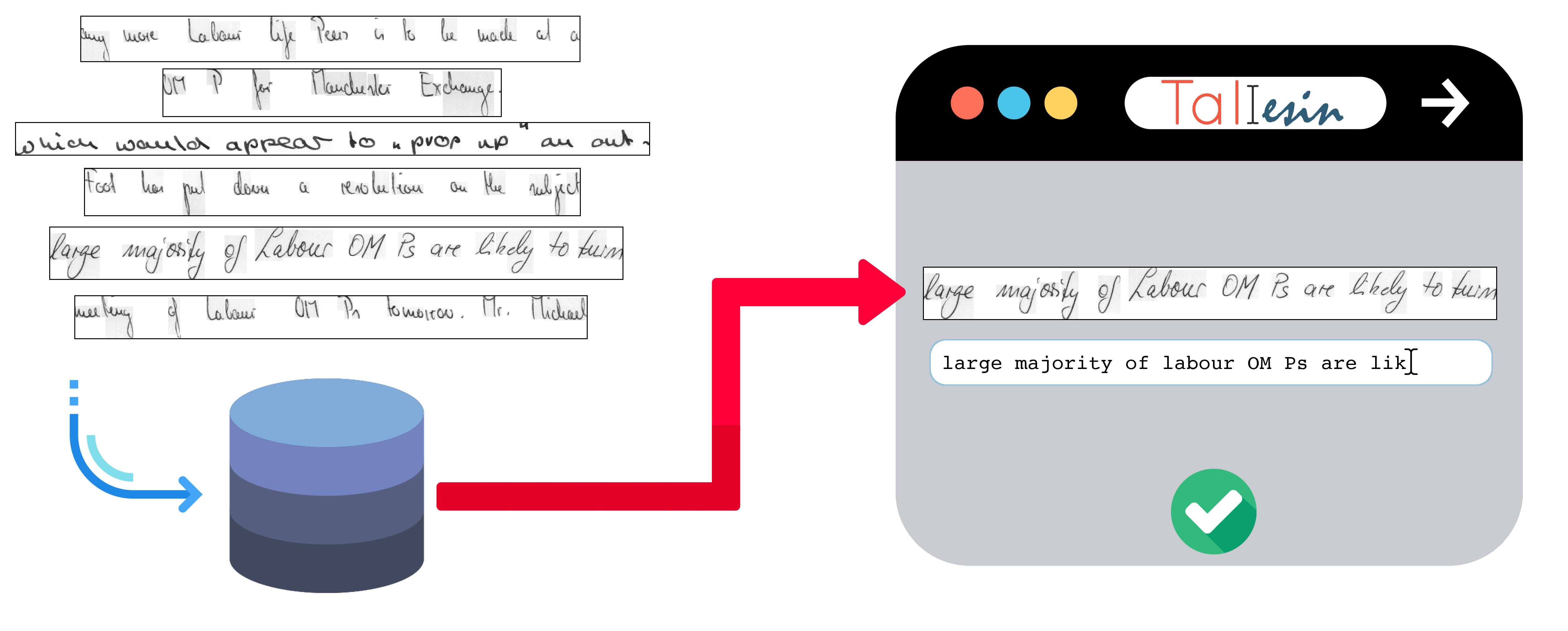
Practically, Taliesin is an application that takes scanned documents as an input and lets the user
annotate them (annotating in this case is associating an image with its transcription).
The application has two modes:
a manual annotation mode, in which the user types the whole transcription of the document
a recognizer assisted mode, in which transcriptions are generated in advance by an internal recognizer. In this mode, the user only validates the transcriptions made by the system or corrects the errors if there are some. During the development and in the first version of the application, we will be using Laia as our recognizer.
In both cases Taliesin generates a dataset of training examples (pairs of an image and its transcription) validated by a human user. Once the database is annotated, the user can simply export these examples and use them as an input for the training of their own recognizer.
Our developing team contains eight students in 4th-year at INSA Rennes in the Computer Science department.
This project was submitted by IRISA's team IntuiDoc, in partnership with Doptim and with the support of Jean-Yves LE CLERC, heritage curator at the Ille-et-Villaine department archives. During the whole year, we have been supervised by Bertrand COÜASNON, teacher at INSA and researcher in the IntuiDoc team, Erwan FOUCHÉ, project manager at Sopra Steria, as well as Julien BOUVET and Alexandre GIMENEZ PUIG, engineers at Sopra Steria. We have also been accompanied by Sophie TARDIVEL, manager and data scientist at Doptim.


In the course of their research, the IntuiDoc team from IRISA, in collaboration with the
Ille-et-Villaine
department archives, aims to make advancements in the handwritten text recognition field in order to
make older documents more accessible. These documents tend to be difficult to understand, indeed the
handwriting of the past centuries and the natural degradation documents suffer from while aging make
them more difficult to read. In this context, automatic recognizers are seen as a promising solution to
extract information from these documents and make them more accessible to the general public.
Developing a software to recognize handwritten text is not easy, that is why most systems are based on
artificial intelligence, and most often neural networks, that need to learn what the different
characters look like, no matter the language and the style of the writer.
To learn this, these systems require an important number of examples (thousands of them), and the
constitution of those collections of examples is a long and tedious process. These example collections
are most often presented as training databases associating an image of a text (the input that the system
will receive) with its transcription (the output that we want our system to give).
Taliesin provides an application that facilitate the generation of these training databases, to
alleviate the researchers' work.


On Taliesin's home page, the user has access to a dashboard presenting all databases currently being annotated. From this page they access all other pages: database annotation or management and recognizer management.

This page is the core of the application, on which the user can type the transcription of
the text
they see in the snippets. Once they have annotated every snippet, the users validate their
work with the green button at the bottom of the page.
The user can enable or disable the automatic transcription suggestions coming from our
recognizer. A small lightning symbol appears next to the pre-filled text field to indicate
that the content comes from our system's recognizer.
The red button with a cross marks a snippet as unreadable.
Of course this page has a lot of keyboard shortcuts to avoid an outstanding number of clicks
and make this work less tedious.

This page is where the user can get all kind of informations about the database currently being annotated (percetage of the database annotated, unreadable, etc.).

This page lets the user manage the handwritten text recognizer. They can set up new
recognizers and train them to make them fit more specifically their database. The
recognizers
will then use this new knowledge to improve their transcription suggestions.
Several measurement points are shown to the user to help them decide what system to use.
Once the recognizer is tuned, it will make more accurate suggestions and speed up the
annotation
process even more.
Taliesin is to become a multi-user web application. In order to deal with a heavy load due to a massive
number of users simultaneously connected, the application has been designed with an architecture based
on
microservices.
This means that the application is divided into several functional blocks running independently from
each other.
In our case, Taliesin is divided into 6 microservices (represented as hexagons on the schema below).
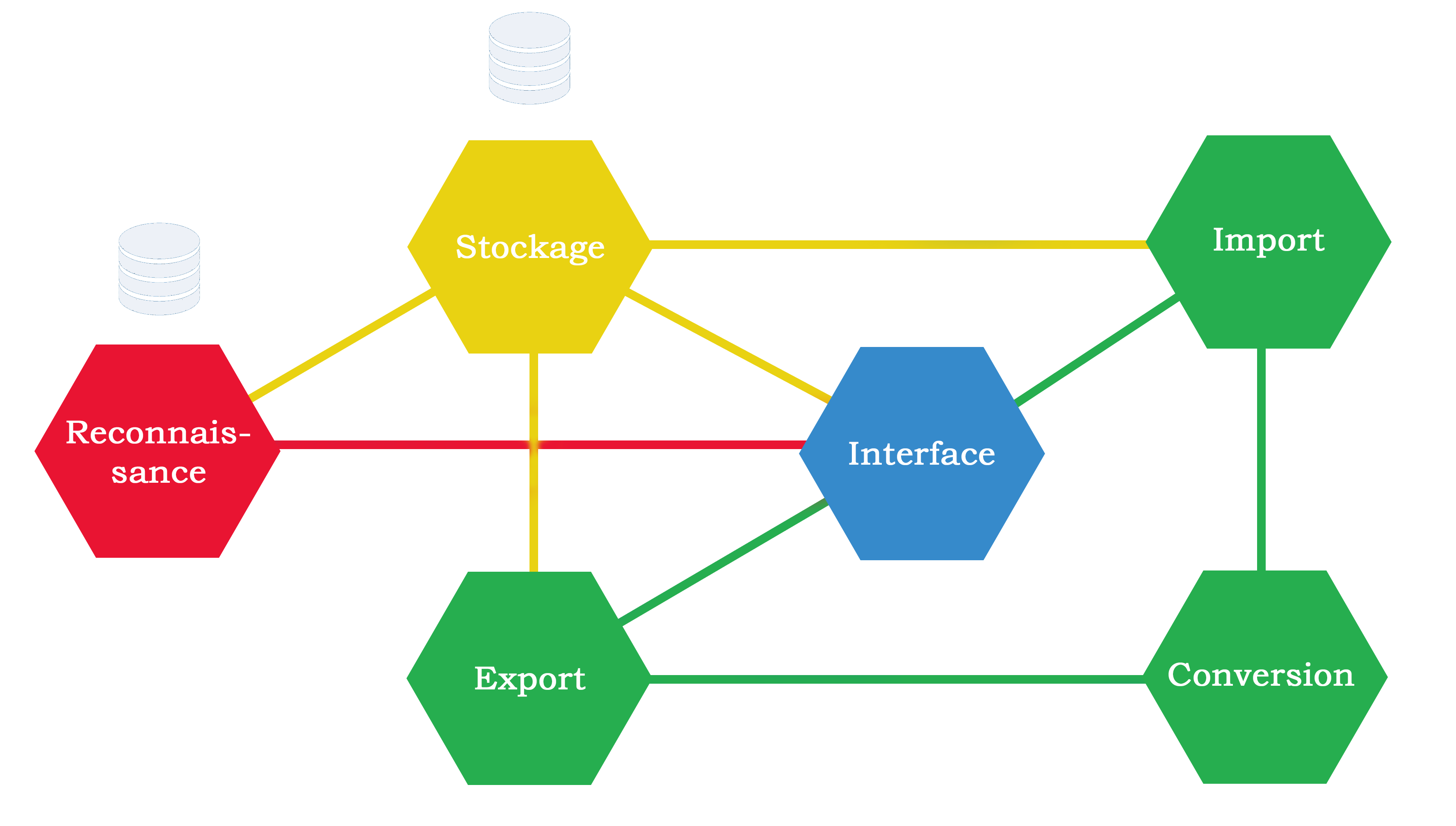
Each microservice is given a specific role, represented by a main functionality. The link between 2
microservices indicates the data exchange between them and the calls they make between each other.
The microservices are presented below.
In the middle you can see the interface, which corresponds to the webpage that the user browses.
The storage service acts as a link for the application's database.
The import service manages the upload of new images in the database.
The export service lets the user export the final database once it has been annotated.
The conversion service is needed at the import and the export, it transforms data from the internal data format to an exploitable one and vice-versa.
The recognizer service manages the automatic recognizer used in the application to make suggestions.
This architecture uses
Kubernetes and
Docker.
Kubernetes is an orchestrator that runs all the application's blocks simultaneously and manages the
communication between them. Each one of Taliesin's microservices is run inside a Docker container.
These containers are an additional encapsulation level that lets Kubernetes manage them independently.
This means it is possible to run the same block several times to answer an increased workload on a
specific part of the application by multiplying the number of instances of one microservice and dividing
the load between them.







