
Notre projet a pour but de fournir une application permettant de simplifier la création de
bases d'images annotées. Ces bases serviront pour l’entraînement de divers systèmes de
reconnaissance d’écriture manuscrite. Ces reconnaisseurs seront par exemple capables de
retranscrire de manière automatique des documents manuscrits (registres paroissiaux,
registres d’état civil, documents d’entreprise, etc.) pour les rendre plus exploitables. Ce
projet permet donc de gagner du temps pour la phase précédant la compréhension de documents
anciens, en simplifiant l’entraînement de systèmes complexes.
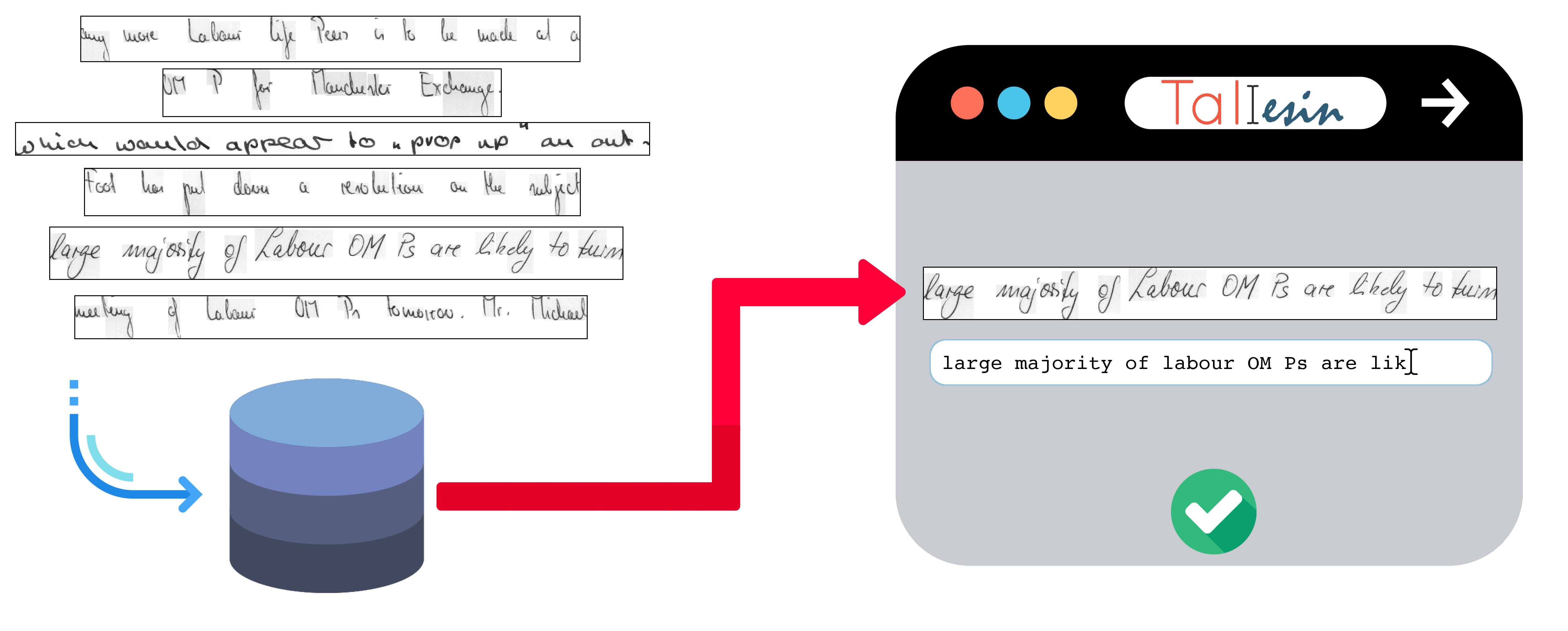
Plus concrètement, Taliesin est une application qui prend des documents scannés en entrée
et qui permet à un utilisateur de les annoter. Cela signifie qu'une transcription est
associée au texte présent dans l'image. L'application propose deux modes à l'utilisateur :
un mode d'annotation manuelle, où l'utilisateur saisit intégralement les transcriptions du document scanné
un mode assisté par un système automatique, où des transcriptions sont générées au préalable par un reconnaisseur d'écriture manuscrite déjà entraîné. Dans ce mode, l'utilisateur n'a plus qu'à corriger les éventuelles erreurs de transcription faites par le reconnaisseur qui l'assiste dans son annotation. Le reconnaisseur utilisé pour la première version de l'application est Laia.
Taliesin génère donc un ensemble d'exemples d'apprentissage (couples image + transcription du texte dans l'image) validés par l'utilisateur. Une fois la base d'images annotée, l'utilisateur n'a plus qu'à exporter les exemples en question qu'il pourra utiliser pour entraîner des reconnaisseurs d'écriture manuscrite.
Notre équipe se compose de huit étudiants en quatrième année au département INFORMATIQUE de l'INSA Rennes.
Ce projet nous a été proposé par l'équipe IntuiDoc de l'IRISA, en collaboration avec la start-up Doptim et avec le soutien de Jean-Yves LE CLERC, conservateur du patrimoine aux archives départementales d'Ille-et-Vilaine. Tout au long de l'année, nous avons été encadrés par Bertrand COÜASNON, enseignant-chercheur membre d'IntuiDoc, Erwan FOUCHÉ, chef de projet chez Sopra Steria et Julien BOUVET ainsi qu'Alexandre GIMENEZ PUIG, ingénieurs chez Sopra Steria également. Nous avons aussi été accompagnés par Sophie TARDIVEL, responsable et data scientist chez Doptim.


Dans le cadre de ses recherches, l’équipe IntuiDoc de l’IRISA, en collaboration avec les archives
départementales d’Ille-et-Vilaine, cherche à faire avancer le domaine de la reconnaissance
d’écriture manuscrite afin de rendre plus accessibles des textes anciens qui sont souvent peu
compréhensibles. En effet, l'écriture manuscrite des siècles passés ainsi que les dégradations dues
au passage du temps diminuent la lisibilité de ces documents. En s'aidant de systèmes automatiques,
cela simplifie ainsi grandement la compréhension et l'extraction d'informations de ces textes
manuscrits.
Il n’est pas simple d’écrire un programme qui reconnaît des textes manuscrits, c’est pourquoi la
plupart des systèmes de reconnaissance d’écriture sont basés sur de l'intelligence artificielle. Ces
algorithmes sont souvent formés de réseaux de neurones qui ont besoin d’apprendre à quoi ressemblent
les différents caractères, peu importe la langue et le style du rédacteur.
Pour apprendre, ils ont besoin d’un grand nombre d’exemples (plusieurs milliers) qui sont longs et
fastidieux à construire à
la main. Ces exemples sont regroupés dans des bases d’apprentissage, associant des images de textes
manuscrits avec leur transcription numérique. Ainsi, l’algorithme apprend à reconnaître les
différentes lettres en comparant la transcription fournie (la vérité) avec les lettres qu'il a reconnu.
Taliesin fournit donc un système qui facilite la génération de ces bases d'apprentissage, afin de
faciliter le travail des chercheurs.


Sur la page d'accueil de Taliesin, l'utilisateur a accès à un tableau de bord recensant l'ensemble des bases en cours d'annotation. Depuis cette page, il peut rejoindre les pages d'annotation, de gestion des bases ou de gestion du reconnaisseur automatique d'écriture.

C'est sur cette page que l'utilisateur peut saisir la transcription du texte contenu dans les
images
qui sont affichées. Après avoir annoté toutes les images, l'utilisateur peut valider les
transcriptions réalisées grâce au bouton vert en bas de page.
L'utilisateur peut activer ou non les suggestions de transcriptions automatiques du
reconnaisseur.
Un petit symbole d'éclair présent à gauche des images permet d'indiquer quand une
transcription est issue du reconnaisseur.
Le bouton en forme de croix rouge à côté de chaque image permet d'indiquer qu'elle n'est pas
lisible.
Des raccourcis sont également disponibles pour remplacer les clics répétitifs et faciliter
l'annotation.

Cette page permet à l'utilisateur d'avoir des informations sur le statut de la base en cours d'annotation (pourcentage d'annotation, nombre d'images illisibles, etc.).

Cette page de l'application donne l'opportunité à l'utilisateur de gérer le système de
reconnaissance automatique mis en place. Il peut ainsi configurer de nouveaux systèmes et
apprendre ces reconnaisseurs, afin d'adapter au mieux le reconnaisseur à ses besoins.
Le reconnaisseur devient ainsi meilleur dans ses suggestions de transcription.
Différentes mesures et statistiques sont fournies à l'utilisateur afin de l'aider à décider
quel système utiliser. Plus un reconnaisseur est performant, moins il se trompe dans ses
suggestions, ce qui accélère l'annotation de la base d'apprentissage.
Taliesin est une application web multi-utilisateurs. Afin de pouvoir gérer une forte charge liée à un
grand nombre d'utilisateurs simultanés, l'application a été conçue avec une architecture en
microservices.
Cela signifie que l'application est découpée en plusieurs sous-blocs fonctionnels et indépendants les
uns des autres. Chaque bloc est donc chargé d'une fonctionnalité en particulier dans l'application.
Dans notre cas, Taliesin est décomposé en 6 microservices (représentés par des hexagones sur le schéma).
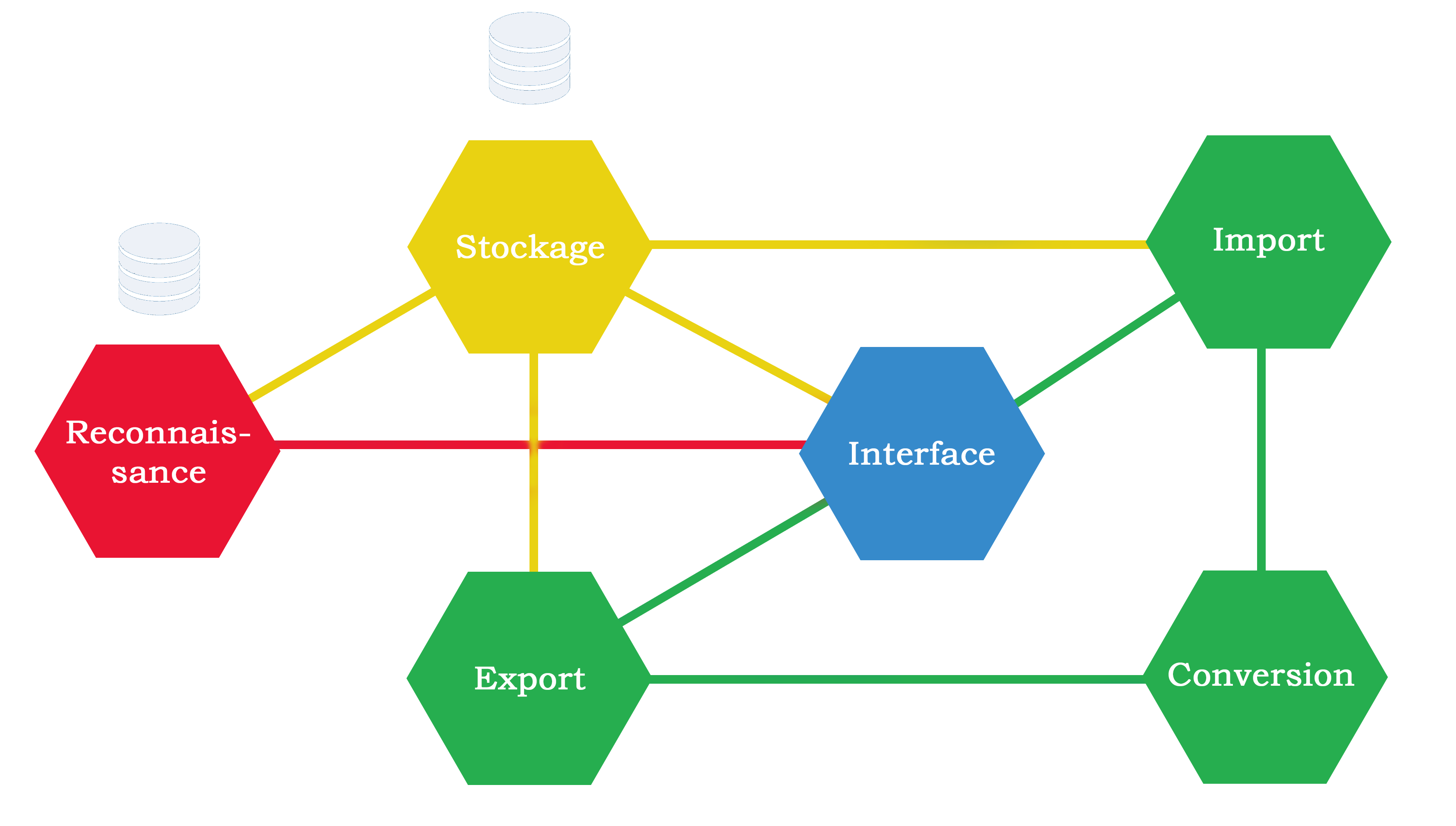
Chaque microservice se voit attribuer un rôle spécifique, représenté par une fonctionnalité principale.
Les liens entre microservices mettent en évidence les échanges de données entre eux et les appels
entre microservices. Les différents blocs sont présentés ci-dessous.
Au centre, on trouve l'interface, qui correspond à la page web sur laquelle l'utilisateur navigue.
Le microservice de stockage fait l'interface avec la base de données de l'application.
Le microservice d'import gère l'ajout d'images dans la base de données.
Le microservice d'export à l'inverse permet à l'utilisateur d'exporter la base finale une fois toutes les images annotées.
La conversion intervient au moment de l'import et de l'export afin de transformer les données vers et depuis un format interne à l'application.
La partie reconnaissance gère le reconnaisseur automatique utilisé dans l'application pour faire des suggestions au cours de l'annotation.
Cette architecture est couplée aux technologies
Kubernetes et
Docker.
Kubernetes est un orchestrateur qui se charge d'exécuter simultanément tous les blocs de l'application,
la rendant opérationnelle.
Chacun des microservices de Taliesin est encapsulé dans un conteneur Docker. Ces conteneurs sont
une surcouche aux microservices qui permet à Kubernetes de les gérer de manière indépendante.
Il est ainsi possible d'exécuter plusieurs fois un bloc de l'application et de répartir les demandes
des utilisateurs entre les différentes copies du microservice.
Grâce à cette organisation, Kubernetes est capable d'adapter le nombre de copies des microservices en
fonction de la charge. Par exemple, si le nombre d'utilisateurs est élevé ou la charge de calcul
demandée par un utilisateur est conséquente, Kubernetes augmentera automatiquement le nombre de
microservices pour suivre la demande.







