Test de notre solution
Testing our solution
Les documents et leurs annotations générés par notre logiciel sont destinés
à constituer un jeu de données pour l’entraînement et le test d’un modèle
d'intelligence artificielle capable d’analyser un document et d’en extraire les données clés.
Au sein de notre groupe, afin de tester la qualité des documents que nous avons généré, nous avons entraîné un modèle d’IA capable
de reconnaître trois éléments communs par la majorité des factures et
de prédire leur boîte englobante qui se présente sous la forme d'une zone rectangulaire de l’image dans laquelle
se situe l’élément détecté par l’IA.
Ces trois éléments sont le total hors taxe (Total HT), le total toutes taxes comprises
(Total TTC) et l’adresse de l’entreprise.
L’IA doit être entraînée grâce aux documents synthétiques.
Les indications obtenus à l’issue des tests nous permettent ainsi de mieux jauger
le niveau d’intensité de variabilité à définir lors de la génération de nos documents
afin qu’une IA puisse correctement généraliser sa prise de décision.
The documents and their annotations generated by our software are intended to constitute a dataset for the training and testing of a model capable of analyzing the structure and extracting data from a document.
In our group, in order to test the quality of the documents we generated, we trained an AI model capable of recognizing three common elements of
the majority of invoices and predict their bounding box.
These three elements are the total excluding tax (Total HT), the total including all taxes (Total TTC), and the company address.
The AI must be trained using synthetic documents.
The indications obtained from the tests allow us to better gauge the level of variability to define when generating our documents so that an AI can correctly generalize its decision-making process.
Ci-dessous un échantillon des résultats obtenus après avoir entrainé un modèle
avec nos propres documents générés.
Below is a sample of the results obtained after training a model with our own generated documents.
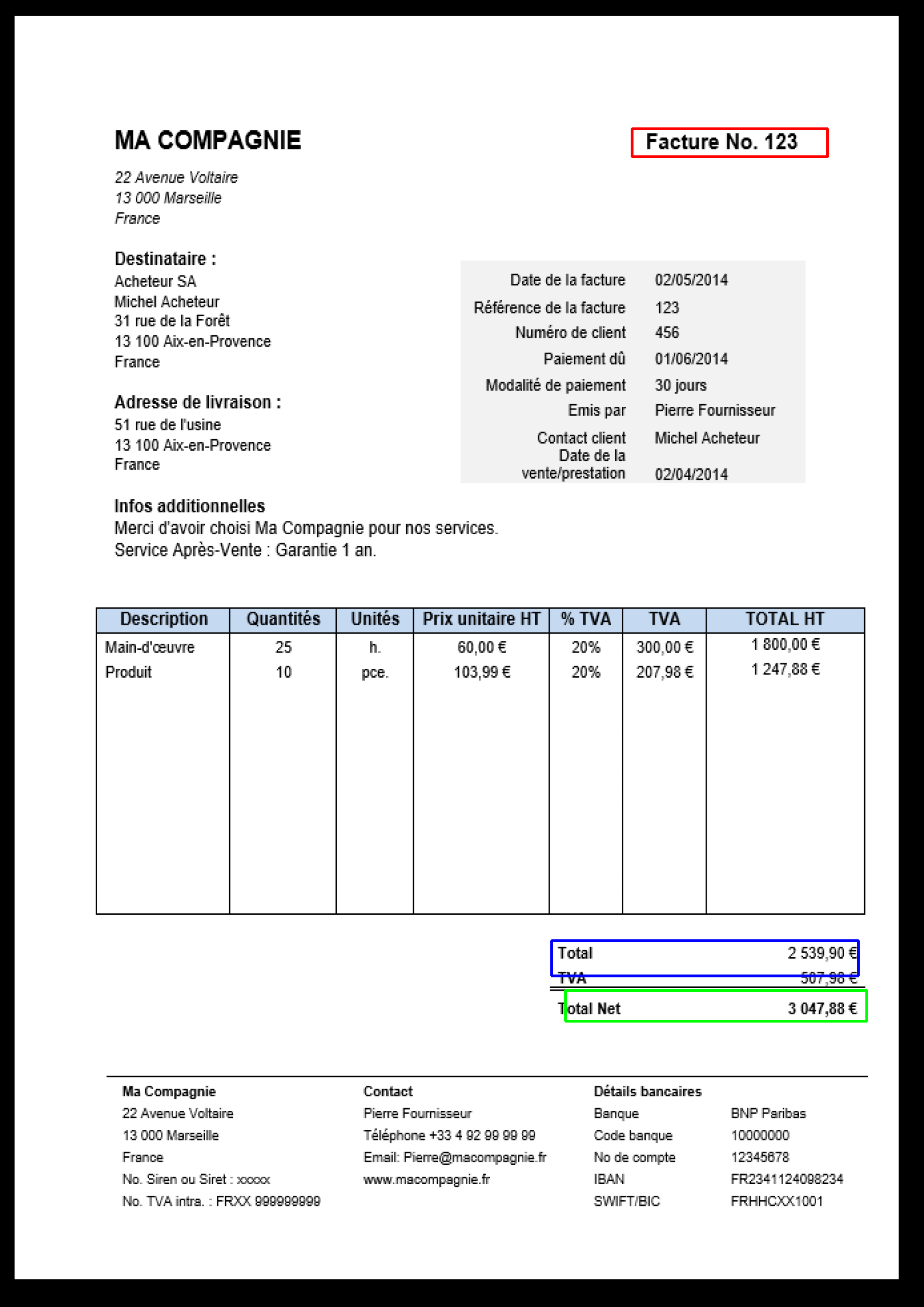
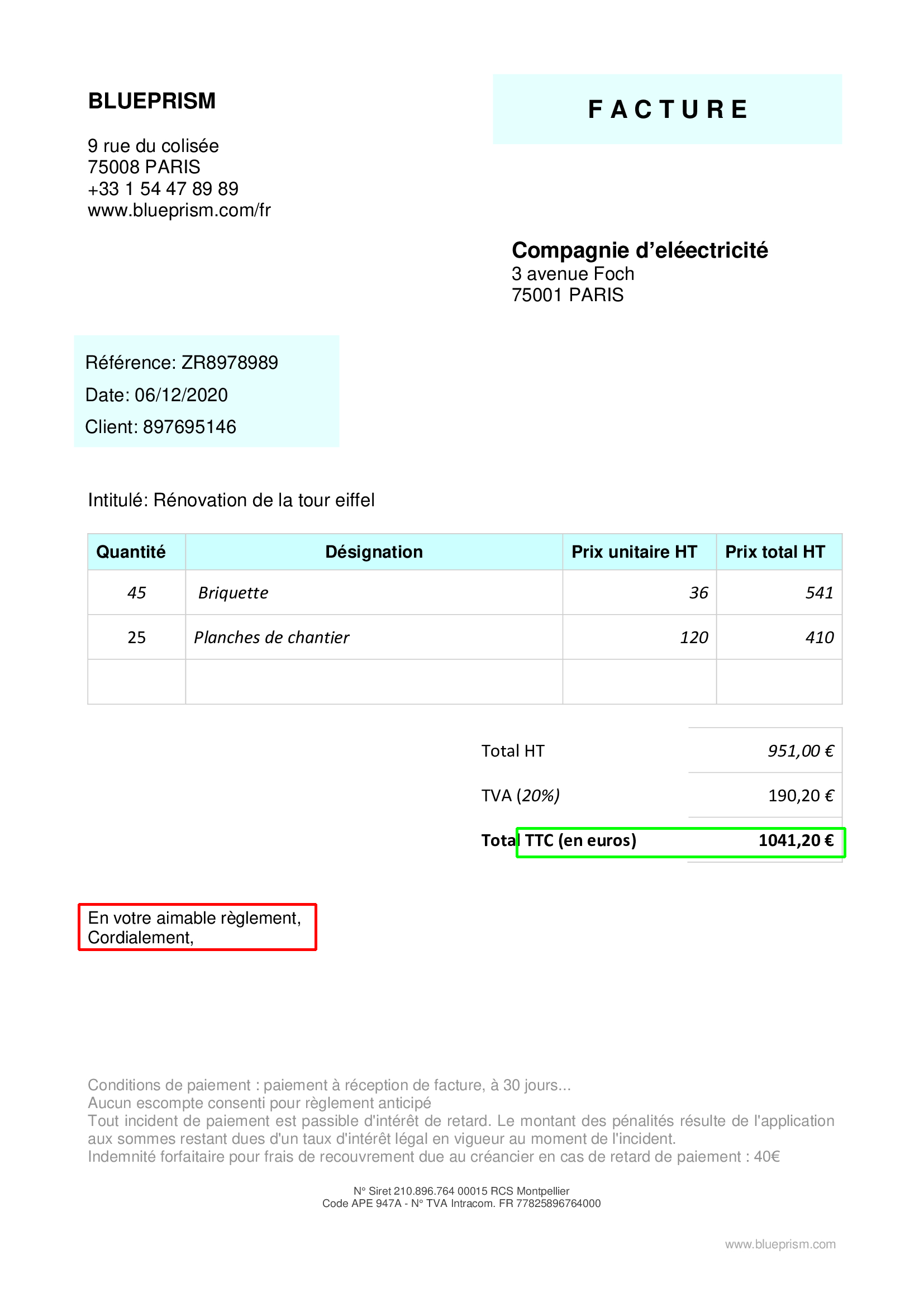
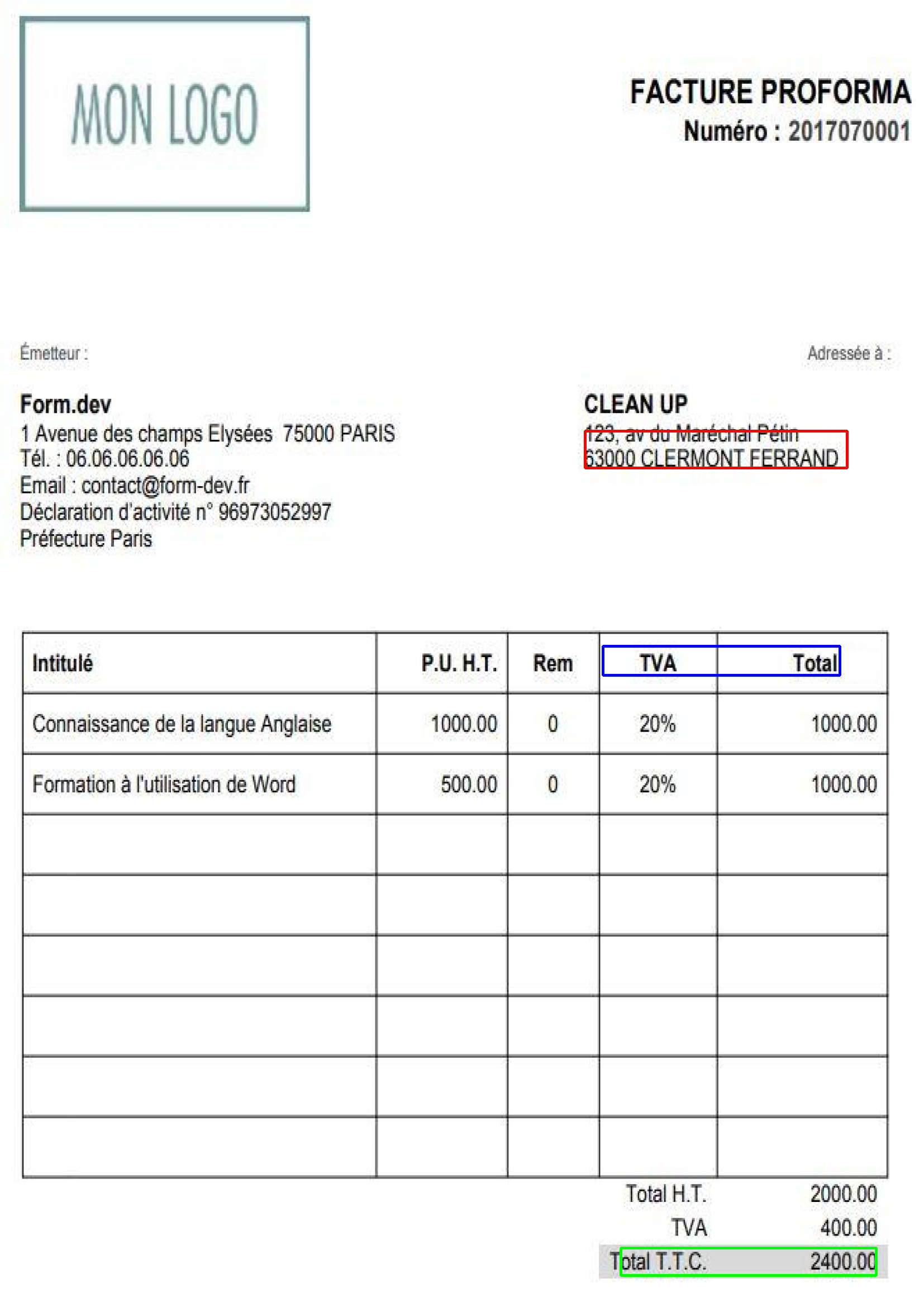
En vert : Total TTC ; en bleu : Total HT ; en rouge : adresse de l’entreprise
On observe que la prédiction du total TTC se fait relativement correctement
mais avec un niveau de confiance très faible. Le total HT n’est pas toujours
prédit et l’adresse est moins bien localisée que les autres informations et quand
elle l’est correctement, le niveau de confiance est bas. On observe aussi une
tendance du réseau à prédire leur position sur des zones où l’on trouve du
texte en gras.
In green: Total TTC; in blue: Total HT; in red: company address
It can be observed that the prediction of the Total TTC is relatively correct,
but with a very low level of confidence. The Total HT is not always predicted,
and the address is less well located than the other information, and when it is
correctly located, the level of confidence is low. There is also a tendency of
the network to predict their position on areas where bold text is present.