The purpose of our project is to provide a program allowing to automatically conceive learning bases to train diverse handwriting recognition systems and to exploit them. For instance, these recognisers will be able to transcribe manuscripts (parish register, civil register, company documents...) into computer texts to make them more easily exploitable. This project will thus allow to save time on the understanding of ancient documents by simplifying the training of complex systems.
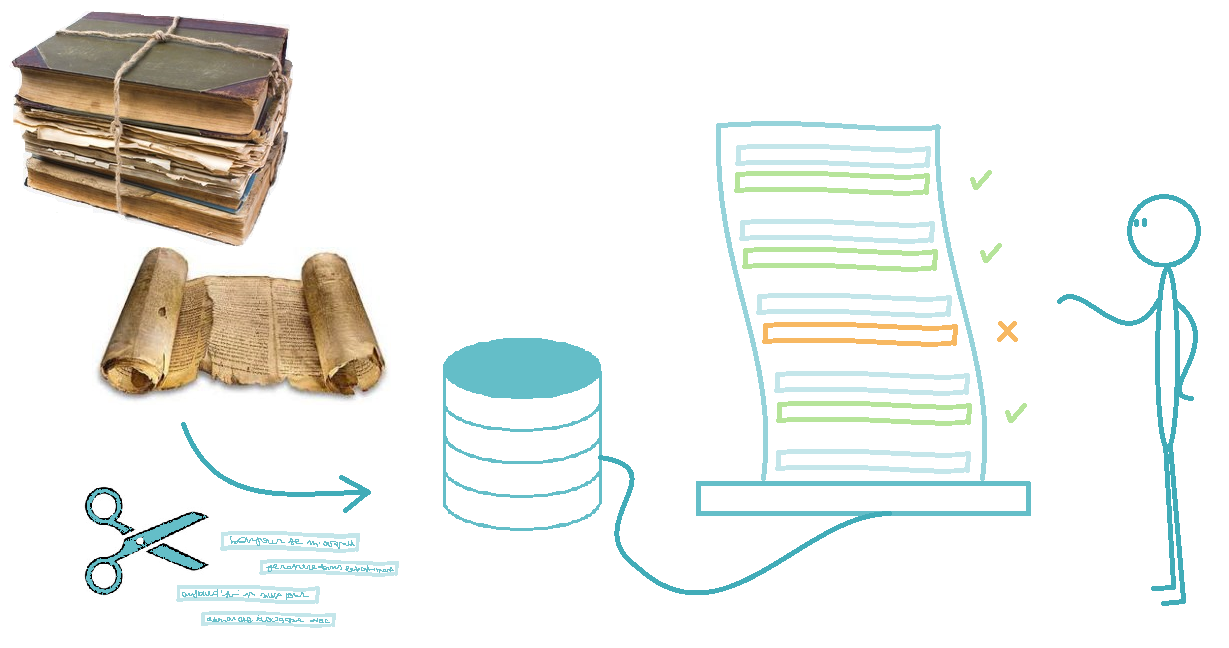
More concretely, Agnosco is a an application which takes scanned documents as input, clips them line by line, then allows the user to create, modify and validate each line's transcription. The app offers the user two modes :
- a manual annotation mode where the user himself types the transcriptions of the scanned document;
- an automatic recognition mode where the transcriptions are generated by a handwriting recogniser. The application allows the user to visualise, modify then validate them.
Therefore, Agnosco generates a set of learning examples which are validated by the user to train handwriting recognisers.

Our team is composed of eight studies in fourth year in the Computer Science department at INSA Rennes.





This project was put forward by the IntuiDoc team from IRISA, in collaboration with the startup Doptim and with the support of Jean-Yves LE CLERC, from the departmental archives curator of Ille-et-Vilaine. Throughout the year, we were supervised by Bertrand COÜASNON, teacher-researcher and member of IntuiDoc, Erwan FOUCHÉ, project manager at Sopra Steria and Julien BOUVET, also engineer at Sopra Steria. We were also accompanied by Sophie TARDIVEL, manager and data scientist at Doptim.
In its researches, the IRISA team IntuiDoc, in collaboration with the Ille-et-Vilaine departmental archives, is working to improve the domaine of handwriting recognition to make ancient documents more accessible. Indeed, the handwriting of the past centuries and the marks of time lessen the documents' readability.
It is quite uneasy to write a program that recognises manuscript texts, that's why most of the handwriting recognisers are based on intelligent algorithms. These latters are often composed of neural networks which need to learn to recognise the different characters, regardless of the language and the writer's style. In order to learn, they need a large amounts of examples (several thousands) which are long and tedious to make by hand.
In this context, the learning bases are associations between the manuscript texts and their computer transcriptions. Thus, the algorithm learns to recognise the caracters by comparing its output with the given transcription. Therefore, Agnosco allows to build a system that automatically generates learning bases from images and a ground-truth to simplify the researchers work.