Résumé de notre projet
Ces dernières années ont vu l'explosion des capacités de stockage des données numériques. La collecte de grandes quantités d'informations est devenue habituelle. Il est possible d'accéder très facilement à de grandes quantités de données : les températures des régions sur les dix dernières années, les achats effectués par des clients de magasins, les résultats d'un sondage répondant à une problématique, etc. Seulement, ces données sont brutes et non-traitées, souvent non étiquetées ou mal étiquetées, bien que recelant une myriade d'informations importantes.
.jpg) Schéma des différentes étapes de fouille de données
Schéma des différentes étapes de fouille de données
La fouille de données est un processus complexe qui consiste à collecter puis à effectuer un traitement sur des données afin de ne garder que les parties les plus pertinentes : ce sont les phases de sélection et prétraitement. Les données ainsi extraites sont ensuite utilisées comme données d'entrée pour certains algorithmes dans une phase de fouille. Les résultats obtenus sont de nouveau traités pendant le post-traitement afin de ne conserver que les résultats pertinents sous forme de motifs, ou patterns. C’est la phase de fouille de données qui pose réellement problème : il faut réussir à sélectionner les algorithmes les plus adéquats, et choisir leurs paramètres afin qu’ils soient performants et qu’ils donnent des résultats intéressants pour l’utilisateur.
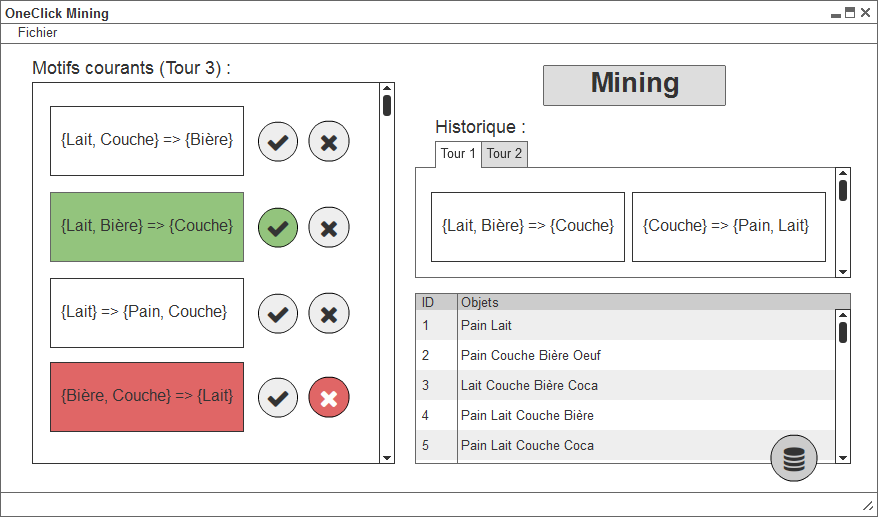
Le projet de quatrième année que nous réalisons consiste en un logiciel de fouille de données, ou data mining, adapté à un utilisateur n'ayant strictement aucune connaissance dans ce domaine : celui-ci aura à cliquer sur un unique bouton afin d'obtenir des résultats. Ce concept est appelé OneClick Mining et est présenté dans l'article de recherche (1)One Click Mining - Interactive Local Pattern Discorvery through Implicit Preference and Performance Learning.
