Summary of our project
During the last years, the data storage capacity in computers has skyrocketed. The gathering of huge quantities of informations has become usual. It is now really easy to have access to these huge data quantities : the temperature about regions of the world during the last ten years, the purchase done by customers in shops, the results of a survey about any problem, etc. However, those data are raw and unprocessed, often without labels or with bad ones, even if those data contains a large volume of important informations.
.jpg) Schematic of the different steps of data mining
Schematic of the different steps of data mining
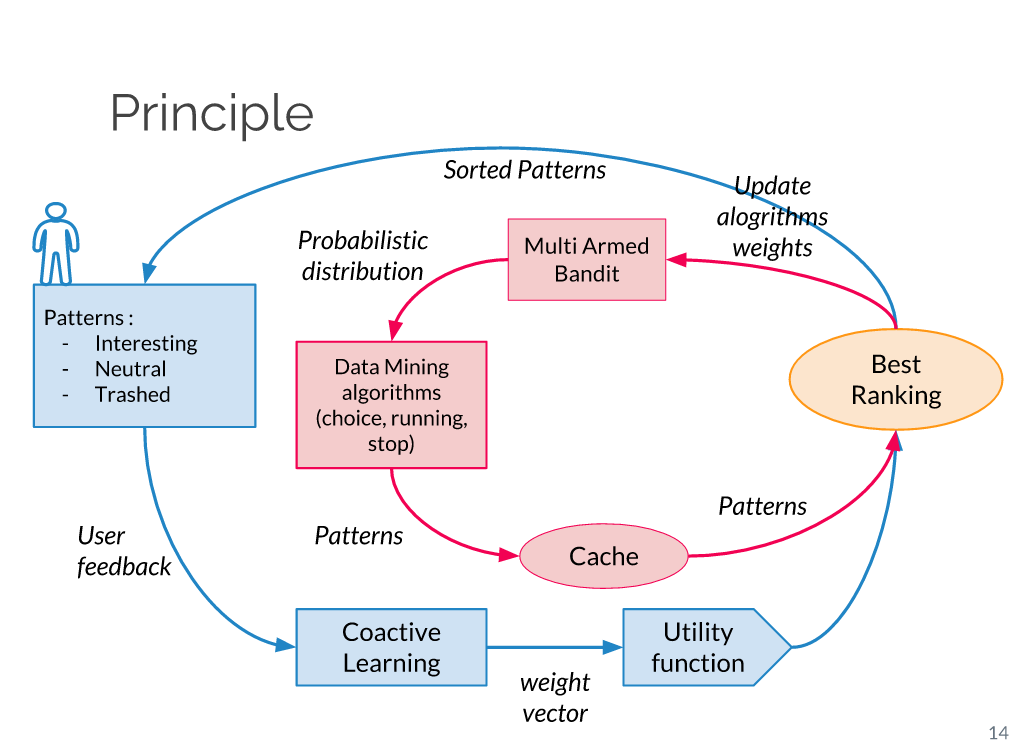
The data mining is a complex process which consist of the gathering then the processing of data to only keep the most relevant parts : these are the selection step and the preprocess step. The data extracted are then used as input for severals algorithms during a mining step. The results obtained are processed one more time during the postprocessing step in order to keep only the relevant ones with a pattern structure. It is the mining step which may cause a problem : we need to select the most appropriate algorithms and choose their parameters so those algorithms perform well and give interesting results for the user.
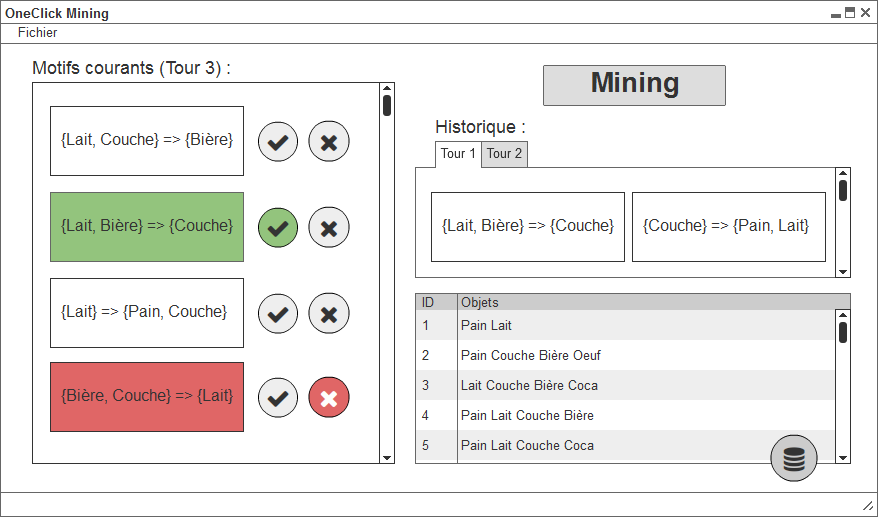
This project for forth-year students is a data mining software, adapted to suit a user who has no experience in data mining. That user would only need to press a unique button to get the results. This concept is called OneClick Mining and is presented in the research article (1)One Click Mining - Interactive Local Pattern Discorvery through Implicit Preference and Performance Learning.